4 - Basic Data Analysis

So far, we have created our own objects by manually entering all of the data in the console. In this section, we will learn how to create objects by importing (aka ‘reading’) data (compiled outside of R) into R, perform basic statistics on it, and visualize it with a histogram.
1. Importing data into R
1.1. Working directory
Before importing your data into R, it is important to understand what the working directory is. The working directory is the location on your computer (i.e., the folder) where R looks for files when importing data and where it saves files. You typically want to have all the files related to a single project in the same folder, so that R can easily find them, and you know where they are saved.
You can check the path of your working directory by running the function getwd() in the console.
⭐ Task 4-1
Check your working directory.
Type in getwd() in the console and hit enter.
Check your code
getwd()
## [1] “A Path to a Folder”
You will get a path to a folder on your computer. This is your current working directory.
More often than not, you will want to change your working directory to a specific folder rather than the default folder. To do that, you can use the setwd() function. Inside the parentheses (i.e. as the function parameter), you should type the path to the folder between quotes. For example, let’s assume you want your working directory to be a folder called “my_project” that is in the main Documents folder. You would type:
setwd("C:/Documents/my_project")
⭐ Task 4-2
Change your working directory.
Change your working directory to a folder where you will keep all the files related to this workshop. Note: You should use forward slashes to denote the path to your folder. This should work on both Mac and Windows.
Check your code
setwd("Path to Folder")
If you are working alone on your scripts, always on the same computer, it is good practice to start every script by setting the working directory using setwd(). However, once you start collaborating with others, the path to the folders can be different between computers. At that point, you might want to learn about R Projects, which makes all paths relative to a pre-specified project working directory. You can read more about it here.
1.2. Importing tabular data
Now that you have your working directory set up, you can import your data into R. R can handle multiple file types:
- .csv (comma-separated values)
- Excel (.xls, .xlsx)
- .txt (and .tsv - tab-separated values)
- .json (used for nested data structures)
- These would likely be arrays of more than 2 dimensions.
- SPSS (another specialized statistics software)
- Data scraped from the web or via an API.
For tabular data, you will most likely be importing .csv or .xlsx files. In this workshop, we will work with .csv files because you can import them with base R. If you have your data in Excel, you can save it as .csv by clicking on File > Save as. If you want to import .xslx files directly, you will need to install a specific package (see here).
⭐ Task 4-3
Download data.
Download and save this spreadsheet of Income data.
- Note: Please save the file in your working directory, specified in the task above.
To import a .csv file in R, you can use the read.csv() function. This function takes as its main argument the name of the file you want to import. This should be in quotes and include the file type.
If you want R to import your file and save it in an object, you need to specify the name of the object and use the <- symbol to assign the imported file to the object:
# This code will create an object called object.name with the data from the .csv file
object.name <- read.csv("path-to-file.csv")
Attention: if you do not assign an object to the imported file, R will simply print the imported data in the console and not save it in an object for future use. Always import data by assigning it to an object.
⭐ Task 4-4
Import data.
Use the function read.csv() to import the dataset of Income data to an object called “income”.
Check your code
income <- read.csv("income.csv")
After running this code, you should see the object “income” in your environment panel in the top right.
If you get an error message that says “No such file or directory”, it’s probably because you did not save the .csv file in your working directory, or because there is a typo in the file name.
There are other functions in R to import other types of tabular data, and a generic function called read.table(), which is really useful if you need to specify some details when importing data, for example, which values to consider NA. To learn more about it, check this.
2. Data frames
Now that you imported your file into R, we can take a closer look at it. The file you just imported is an object of the type data frame.
To check that, you can run the code:
# The function class() tells you the type of object. It is good for checking if you imported your files correctly
class(income)
## [1] "data.frame"
Definition - Data frame: essentially a table. It is a two-dimensional object that can hold different types of data.
- Usually, data frames are used to store values of variables (i.e. the columns) recorded for different observations (i.e. the rows). For example, different observations made for different cats.
- Data frames can contain one or more columns and one or more rows.
- All values in a column are related (e.g., column 1 = age, column 2 = eye color)
- Because the column contains the same type of information, it is equivalent to a vector (i.e., the ‘eye color’ column will contain characters, not numbers).
- One row denotes one object from the set. For example, in the data frame of information about a set of cats, each row contains information about one specific cat.
- A row can contain many different bits of information, like age (numerical), eye color (character), breed (character), whether or not it’s spayed/neutered (boolean). Because rows may contain values of different types, one row would most likely not be a vector. It would likely be a list, which can contain values of different types.
To see the data in your data frame, simply enter the name of the data frame in the console and type ‘enter’ or ‘return’.
income
The following will be the output:
## id gender income experience
## 1 1 M 23000 3
## 2 2 M 55000 7
## 3 3 M 43000 5
## 4 4 F 37000 5
## 5 5 M 75000 9
## 6 6 M 72000 10
## 7 7 F 121000 13
## 8 8 F 27000 1
## 9 9 F 57000 8
## 10 10 F 91000 10
Another useful way to inspect your data frame is to use the str() function:
str(income)
## 'data.frame': 10 obs. of 4 variables:
## $ id : int 1 2 3 4 5 6 7 8 9 10
## $ gender : chr "M" "M" "M" "F" ...
## $ income : int 23000 55000 43000 37000 75000 72000 121000 27000 57000 91000
## $ experience: int 3 7 5 5 9 10 13 1 8 10
This tells you that your data frame is made of 10 observations of 4 variables. It can be inferred that this data relates to 10 people. It then tells you the name of each variable (id, gender, income, experience), the data type of each variable (int = integer, chr = character), and the first few values of each column.
You can use de $ symbol to refer R to specific columns inside your dataframe. For example, if you want to check the individual values for gender, you can type:
income$gender
## [1] "M" "M" "M" "F" "M" "M" "F" "F" "F" "F"
These columns are treated as vectors in R, so if you wanted to get the 4th value of the column gender, you can use the indexing inside [] that you learned in the previous section:
income$gender[4]
## [1] "F"
We will explore other ways to view and preview the content of our data frames in Activity 5. You can also go here for more information about data frames.
3. Summary statistics.
Statistics is:
- the science of collecting, analyzing, and interpreting
- data to uncover patterns and trends,
- and inform decisions based on this data.
If you’re unfamiliar with statistics, you can learn more about it from the w3school Statistics Tutorial
In this section, we’ll be focusing on
- Basic statistical measures
- Presenting data in a histogram
- More on presenting data will be covered in Activity 6-Data Visualization
3.1 Basic statistical measures
The function names for the following three statistical measures (mean, median, standard deviation) are quite intuitive.
It is just the name or abbreviation of the statistical measure, where the argument is the object containing the set of values we are analyzing.
Each function takes the vector containing the values of the variable as its argument.
These three functions are designed for sets of numerical and integer data types. If run on other types (character, aka text, and boolean, aka true/false), the result will be NA.
⭐ Task 4-5
Get the mean (average) income.
Mean: the average value in a set.
The mean() function calculates the sum of the values in the set and divides the sum by the number of items in the set.
Write and execute a command that outputs the mean income across the 10 people in our dataset. Remember: you can use the $ symbol to extract one column (i.e., one vector) from your data frame.
Check your code
# output the average income
mean(income$income)
## [1] 60100
⭐ Task 4-6
Get median value.
Write and execute a command that outputs the median value of income
Median: The middle value in a sorted set (e.g. lowest - highest). median()
Check your code
median(income$income)
## [1] 56000
The output tells you the income value that falls between the higher income half and the lower income half of the people in your dataset.
⭐ Task 4-7
Get standard deviation.
Standard deviation: Describes how spread out the data is.
The function in R is sd()
Write and execute a command that outputs the standard deviation of the income.
The output tells you how much the individual incomes vary from the average income.
- A small standard deviation means that most people have an income that is close to the average, indicating uniformity in income.
- A large standard deviation suggests a wide range of incomes.
Check your code
sd(income$income)
## [1] 30479.32
Up until now, you were calculating mean, median and standard deviation for one single variable in your data frame. However, often you will want to calculate that for the entire dataframe. For this, a useful function is summary(), which takes a data frame as input and returns a summary of each variable as the output.
⭐ Task 4.8
Get summary of statistics.
Display a summary of statistics for the income data.
Check your code
summary(income)
## id gender income experience
## Min. : 1.00 Length:10 Min. : 23000 Min. : 1.00
## 1st Qu.: 3.25 Class :character 1st Qu.: 38500 1st Qu.: 5.00
## Median : 5.50 Mode :character Median : 56000 Median : 7.50
## Mean : 5.50 Mean : 60100 Mean : 7.10
## 3rd Qu.: 7.75 3rd Qu.: 74250 3rd Qu.: 9.75
## Max. :10.00 Max. :121000 Max. :13.00
4. Histograms
Histogram: A graph used for understanding and analysing the distribution of values in a vector.
A histogram illustrates:
- Where data points tend to cluster
- The variability of data
- The shape of variability
The histogram will appear in the Plots tab (bottom right quadrant if you haven’t modified your RStudio layout).
To create a histogram, you can use the function hist(). For example, for a histogram of the income data:
# Remember that income$income grabs the variable "income" in the data frame "income"
hist(income$income)
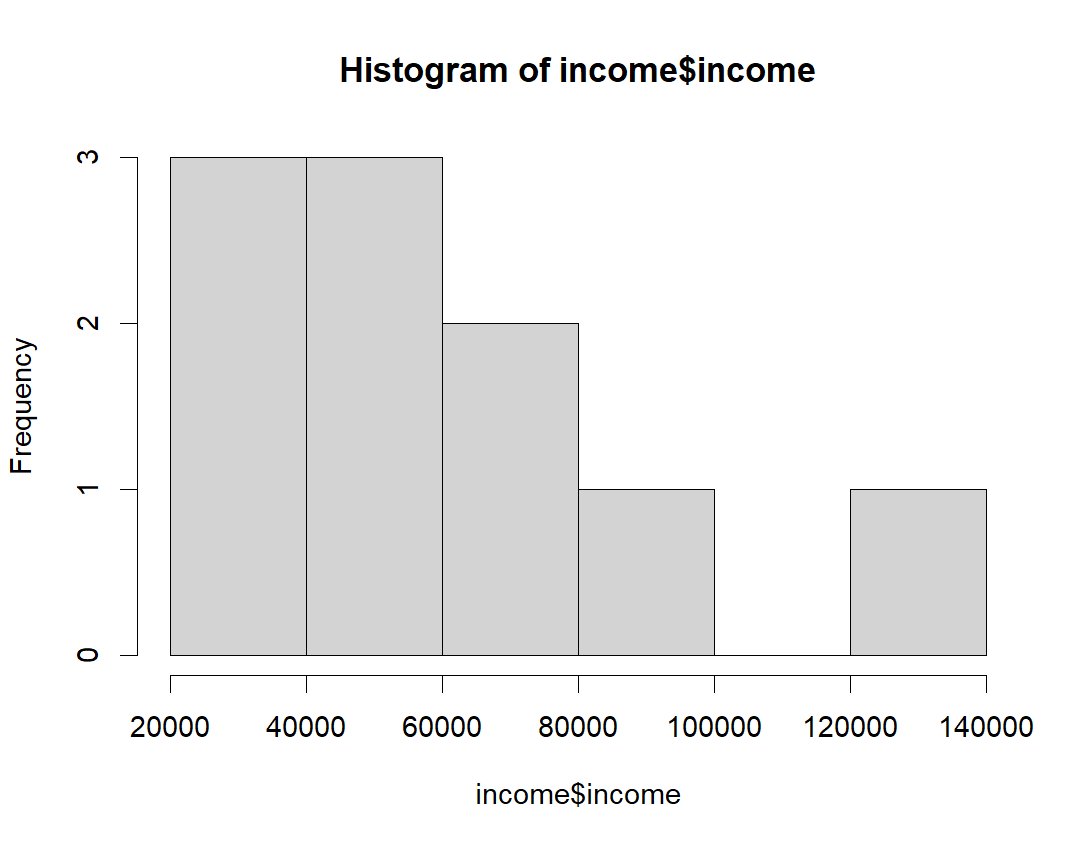
We can also pass in additional parameters to control the way our plot looks.
Some of the frequently used parameters are:
main: The title of the plot- e.g.,
main = "This is the Plot Title"
- e.g.,
xlab: The x-axis label- e.g.,
xlab = "The X Label"
- e.g.,
ylab: The y-axis label. “Frequency” is the default value, and you don’t have to specify it unless you would like a different label.- e.g., ylab = “The Y Label”
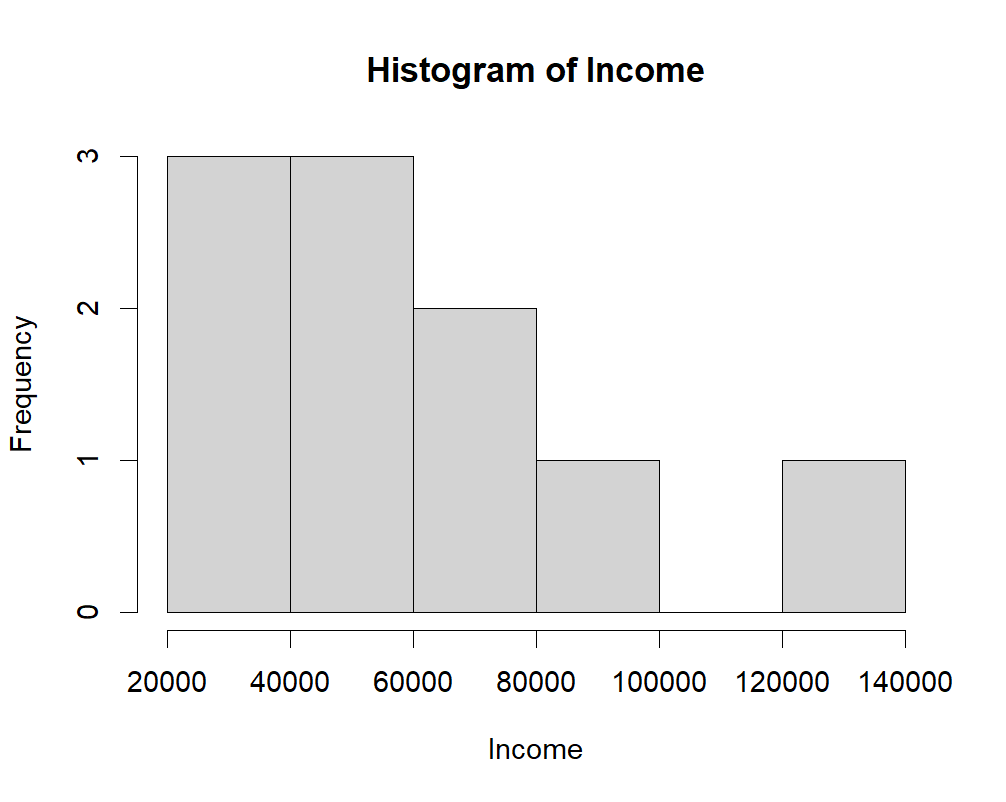
Multiple parameters are given to a function by putting them in parentheses separated by commas, function_name(parameter1, parameter2):
# The first parameter is the name of the data (vector) object
# 'main' is the graph title
# 'xlab' is the label of the x-axis
# label parameters can be in any order, but following the data object
# y-label on a histogram defaults to "frequency". You can add 'ylab=""' if you'd like.
hist(income$income, xlab="Income", main = "Histogram of Income")
⭐ Task 4-9
Create a histogram.
Create a histogram for the experience data using the histogram function hist(). Remember to add an informative title and labels.
- Parameter: vector of values to plot
Check your code and see the histogram
hist(income$experience, main = "Histogram of Experience", xlab = "Experience")
The following will be the output:
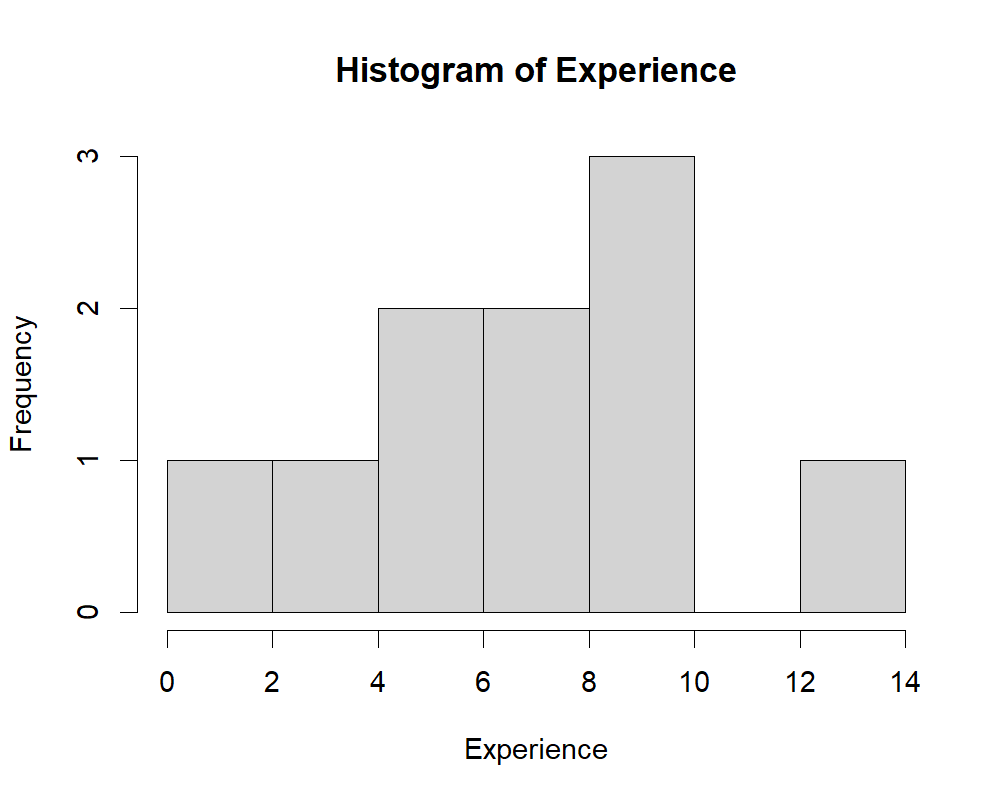
We can see in the histogram that there are 7 intervals with equally spaced breaks. In this case, the height of a cell is equal to the number of observations falling in that cell.
- Why are there 7 intervals? R automatically chooses the number of intervals for you.
Additional: If you preferred having fewer or more intervals (i.e., ‘bins’), use can set that using the breaks parameter.
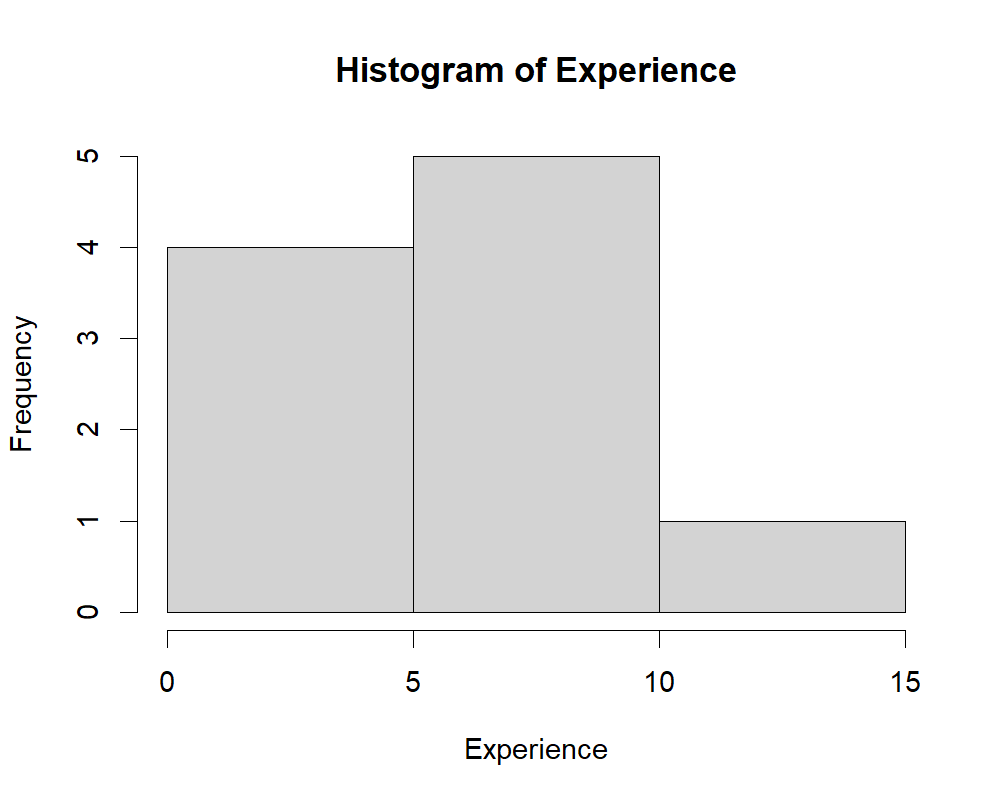
⭐ Task 4-10
Create a histogram with a different number of intervals.
Use the argument breaks inside the function hist() to create a histogram of experience that has only 3 intervals.
Check your code
# breaks is equal to the number of intervals
# You can add the custom labels if you would like `main='Histogram of Experience',xlab='Experience', `
hist(income$experience, main = "Histogram of Experience", xlab = "Experience", breaks = 3)