Data visualization
If you and your group have any questions or get stuck as you work through this in-class exercise, please ask the instructor for assistance. Have fun!
An important part of checking and analyzing data is making figures with your data to visualize the main distributions of variables, trends of association between variables etc. In this activity, you will learn how to use the ggplot2 package (part of the tidyverse package) to create figures. The ggplot2 package is a popular system for creating data visualizations like plots, charts, graphs, etc.
In this activity, you will make a histogram, a boxplot, a scatter plot, a bar chart, and a line chart.
Before you start this activity, let’s give your RStudio session a fresh start. For that:
- Save your previous scripts by clicking on File > Save, or on the save icon on the top left. If needed, choose a folder to save it (probably the working directory you were working on in the previous activity) and give it a meaningful name.
- Close the script by clicking on File > Close or on the x next to the file name on the top left.
- Clean your R environment (i.e., remove all the objects) by clicking on the broom icon
 on the top right and clicking yes on the pop-up window that appears.
on the top right and clicking yes on the pop-up window that appears. - Create a new script by clicking on File > New File > R Script, or on the New Script icon
 on the top left.
on the top left.
1. Getting Ready
1.1 Prepare your working environment
You will use the tidyverse. You should already have the tidyverse package installed on your computer for previous activities.
⭐ Task 3-1
Prepare your working environment.
Prepare your working environment by loading the tidyverse packages (the ggplot2 package is part of the tidyverse package) and setting your working directory.
Check your code
# load packages
library(tidyverse)
# set working directory
setwd("path-to-folder") # Remember to substitute "path-to-folder" by the actual path to your folder
1.2 Load your data
From this link download the following data we have prepared for you to use in this activity. Save the file in your working directory. This is a dataset that shows information about different cocoa bars such as percent cocoa, company location, cocoa bean type and rating.
⭐ Task 3-2
Read your data set.
- Data set file name:
flavors_of_cacao.csv - Name your dataframe:
chocolateData
Check your code
# read data
chocolateData <- read.csv("flavors_of_cacao.csv")
Hint: See Activity 1 for instructions on importing a .csv file.
1.3 Check your data
As you are probably aware at this point, you always want to check your data to make sure it was properly imported and identify any data cleaning that is needed.
⭐ Task 3-3
Preview the first 5 rows of your chocolate data.
Check your code
# Check data
chocolateData |>
# Preview first 5 lines of chocolateData
head(5)
## company specific_bean_origin_bar_name ref review_date cocoa_percent
## 1 A. Morin Carenero 1315 2014 70
## 2 A. Morin Sur del Lago 1315 2014 70
## 3 A. Morin Puerto Cabello 1319 2014 70
## 4 A. Morin Madagascar 1011 2013 70
## 5 A. Morin Chuao 1015 2013 70
## company_location rating bean_type broad_bean_origin
## 1 France 2.75 Criollo Venezuela
## 2 France 3.50 Criollo Venezuela
## 3 France 3.75 Criollo Venezuela
## 4 France 3.00 Criollo Madagascar
## 5 France 4.00 Trinitario Venezuela
Another way to inspect your data is to use the str() function.
⭐ Task 3-4
See the structure of your data.
Check your code
# Check structure of data
str(chocolateData)
## 'data.frame': 907 obs. of 9 variables:
## $ company : chr "A. Morin" "A. Morin" "A. Morin" "A. Morin" ...
## $ specific_bean_origin_bar_name: chr "Carenero" "Sur del Lago" "Puerto Cabello" "Madagascar" ...
## $ ref : int 1315 1315 1319 1011 1015 1470 705 705 705 705 ...
## $ review_date : int 2014 2014 2014 2013 2013 2015 2011 2011 2011 2011 ...
## $ cocoa_percent : num 70 70 70 70 70 70 60 80 88 72 ...
## $ company_location : chr "France" "France" "France" "France" ...
## $ rating : num 2.75 3.5 3.75 3 4 3.75 2.75 3.25 3.5 3.5 ...
## $ bean_type : chr "Criollo" "Criollo" "Criollo" "Criollo" ...
## $ broad_bean_origin : chr "Venezuela" "Venezuela" "Venezuela" "Madagascar" ...
We can see that the dataset is composed of 1795 observations of chocolates, where 9 variables have been measured. The result also shows you the names of the variables and the type of each variable. It seems like this dataset is cleaned and ready to go. When working with your own dataset, you would want to make sure it passed certain data validation commands such as the ones learned in Activity 1 before continuing with data exploration and analysis. Here, we know this dataset is cleaned and can be used for the plotting activities.
📍 Reminder! Save your work
2. Creating plots and charts in ggplot2
Here is some information about creating and formatting plots, common to all types we will look at in this activity. Don’t do anything yet!
The command to begin plots and charts are very similar. Let’s first look at the commonalities. For all of them, we will use the ggplot() function and a geometry function. ggplot() parameters are:
- The dataset used for the plot
data = datasetName - The aesthetic mappings. This specifies which column values are assigned to the x-axis, and which are assigned to the y-axis.
aes(x = columnForXAxis, y = columnForYAxis)
The geometry function is attached to the ggplot() function with+ geom_ and is completed by the type of plot or chart:
- histogram:
geom_histogram() - boxplots:
geom_boxplot() - scatter plot or point plots:
geom_point() - bar charts:
geom_bar()orgeom_col() - line charts:
geom_line()
Plots will appear in the “Plot” tab (probably in the bottom right hand quadrant of your RStudio window).
2.1 Histograms
Histograms are very helpful plots to look at the distribution of your variables. We already learned how to plot them using base R commands in the Introduction to R workshop, and now we will learn how to plot them using the ggplot2 package.
The function to plot a histogram is geom_histogram(). To use this function, you only need to specify one variable, and ggplot will automatically count the number of observations in each bin of the variable for you.
For example, to make a histogram of the cocoa percentage in chocolate bars:
# Create plot by specifying data and assign variable to the x axis
ggplot(data = chocolateData, aes(x = cocoa_percent)) +
geom_histogram() # then add a layer of histogram bars
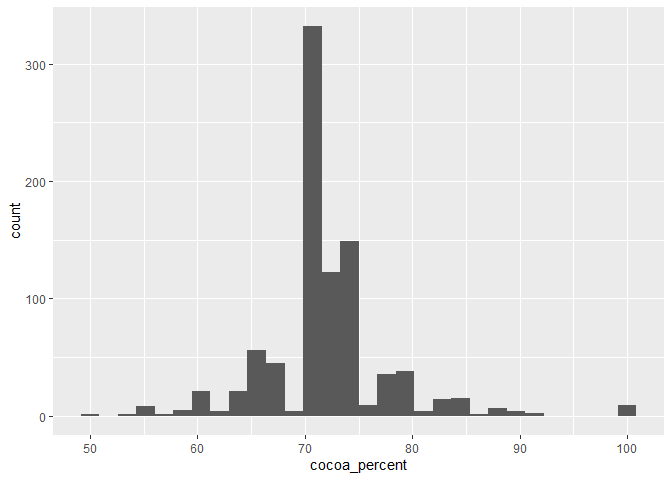 As you can see, the
As you can see, the cocoa_percent variable was assigned to the x-axis, as specified, and the y-axis was automatically assigned to the count of observations in each bin.
When plotting a histogram, you can also specify the width of the bins through the argument binwidth or the number of bins to be used through the bins argument.
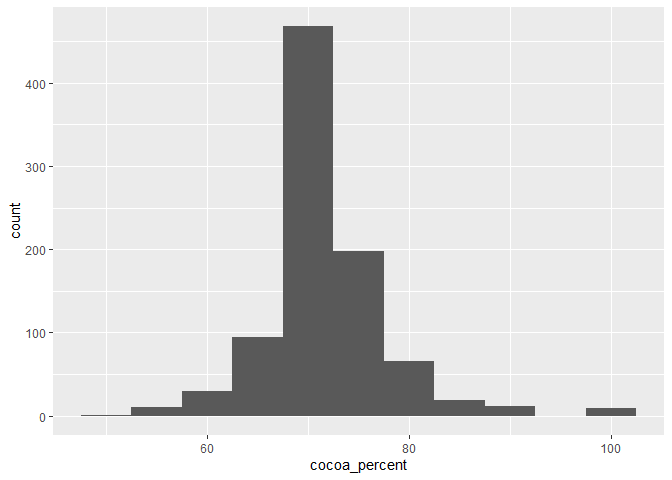
⭐ Task 3-5
Make a histogram of the cocoa percentage of bars.
- Using chocolate data :
chocolateData - X-axis = cocoa percentage of chocolate bars:
coca_percent - Choose
binwidth = 5inside thegeaom_histogram()function to force the bin width to be 5% (it always uses the scale of the x variable)
Check your code
# Create plot by specifying data and assign variables to the x axis
ggplot(data = chocolateData, aes(x = cocoa_percent)) +
geom_histogram(binwidth = 5) # then add a layer of histogram bars, with binwidth equals to 5%
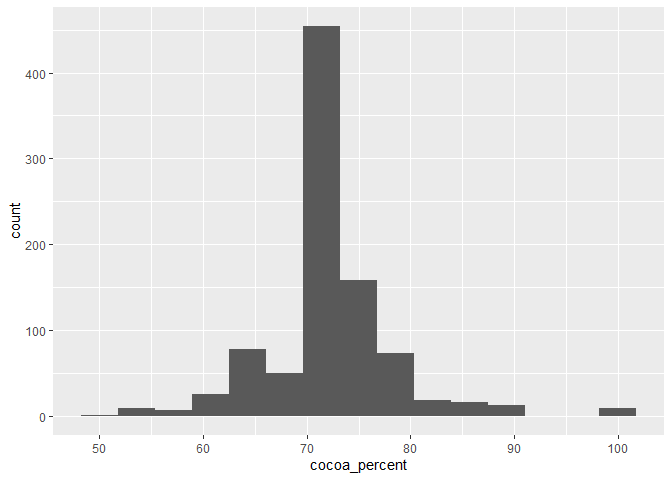
⭐ Task 3-6
Make a histogram of the cocoa percentage of bars.
- Using chocolate data :
chocolateData - X-axis = cocoa percentage of chocolate bars:
coca_percent - Choose
bins = 15inside thegeaom_histogram()function to force the plot to have 15 bins
Check your code
# Create plot by specifying data and assign variables to the x axis
ggplot(data = chocolateData, aes(x = cocoa_percent)) +
geom_histogram(bins = 15) # then add a layer of histogram bars, with 15 bins
You can also specify the axes labels and a title for your axis using the labs() function:
+ labs(title = "", x = "", y = " ")
# Create plot by specifying data and assign variable to the x axis
ggplot(data = chocolateData, aes(x = cocoa_percent)) +
# then add a layer of histogram bars, with 15 bins
geom_histogram(bins = 15) +
# add labels and title tot he plot
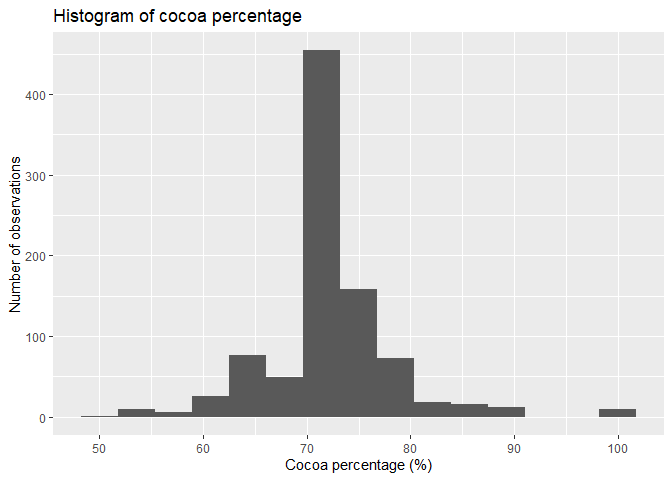
labs(title = "Histogram of cocoa percentage",
x = "Cocoa percentage (%)",
y = "Number of observations")
2.2 Boxplots
Boxplots are another way to see the distribution of your data, by showing key statistical features of your data:
- Median: the line that divides the boxplots shows the median of your data
- Quartiles: the top and bottom ends of the boxes represent the upper and lower quartiles of your data
- Range: the lines extending from the boxes shows the range of values, excluding outliers
- Outliers: dots or other markers beyond the whiskers show potential outliers in your data
If you want to know more about boxplots, check out this link.
The function to plot a boxplot is geom_boxplot(), and in the same way as the histogram, it requires only one variable to be specified (usually the y-axis, but you could also use the x-axis).
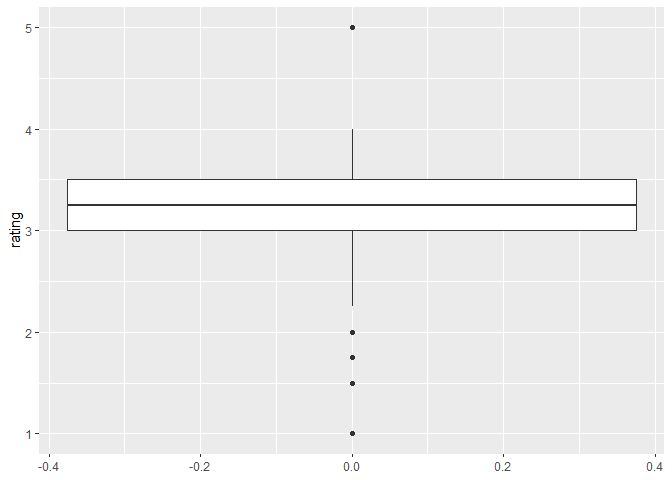
For example, to plot the boxplot of the ratings chocolate bars received
# Create plot by specifying data and assign variable to the y axis
ggplot(data = chocolateData, aes(y = rating)) +
# then add a layer of boxplot
geom_boxplot()
 Boxplots can be useful if you want to compare the distribution of a variable between different categories. For example, imagine you want to know if the rating of chocolate bars varies according to the bean type. You can then specify
Boxplots can be useful if you want to compare the distribution of a variable between different categories. For example, imagine you want to know if the rating of chocolate bars varies according to the bean type. You can then specify bean_type as the second variable (for the x-axis) in the plot.
⭐ Task 3-7
Make a boxplot of the rating chocolate bars received by bean type
- Using chocolate data :
chocolateData - X-axis = Bean type:
bean_type - Y-axis = Rating chocolate bars received:
rating - Remember to add descriptive labels and a title to your plot using the
labs()function
Check your code
# Create plot by specifying data and assign variable to the y axis
ggplot(data = chocolateData, aes(y = rating, x = bean_type )) +
# then add a layer of boxplot
geom_boxplot() +
# add labels
labs(title = "Rating by bean type",
x = "Bean type",
y = "Rating")
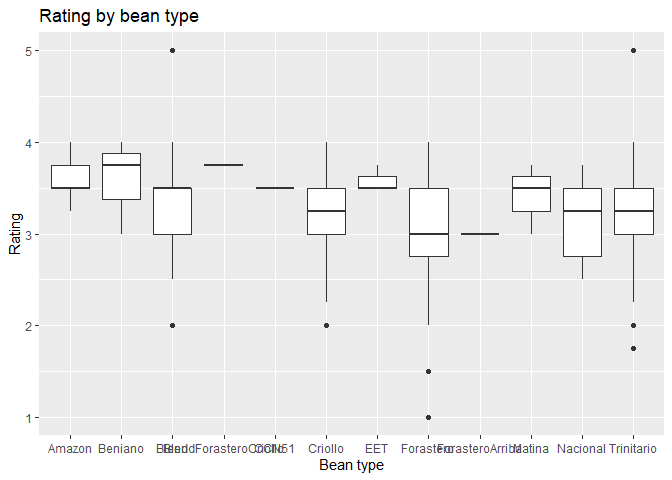
As you can see, some bean types, such as “Trinitario” have more variable ratings, while others, such as “Amazon” have consistently higher ratings.
However, the plot is hard to interpret, as there are many bean types. In this case, it might be best to plot only the most common bean types. For that, we first need to create a new dataset that contains only the most common bean types.
# Get the most common bean types
bars_per_type <- chocolateData |> # get the dataframe
group_by(bean_type) |> # group by bean type
count() # count the number of bars per bean_type
# check the new data frame
bars_per_type
## # A tibble: 12 × 2
## # Groups: bean_type [12]
## bean_type n
## <chr> <int>
## 1 Amazon 5
## 2 Beniano 3
## 3 Blend 41
## 4 BlendForasteroCriollo 1
## 5 CCN51 1
## 6 Criollo 213
## 7 EET 3
## 8 Forastero 195
## 9 ForasteroArriba 1
## 10 Matina 3
## 11 Nacional 5
## 12 Trinitario 436
Now, we want to get the list of the most common bean types. Looking at the data above, you could decide to use 10 as a threshold of a sufficient number of bars being produced.
# Get most common bean types
common_bean_types <- bars_per_type |> # get the data
filter(n > 10) |> # filters for rows where the variable n is larger than 10
pull(bean_type) # gets the column with bean type names
# check common bean types
common_bean_types
## [1] "Blend" "Criollo" "Forastero" "Trinitario"
There are four types of beans with more than 10 chocolate bears being produced. Finally, we can then filter the original dataset only for the rows with these bean types.
# Filter chocolateData to only include common beans
chocolateData_commonBeans <- chocolateData |> # Get the data
filter(bean_type %in% common_bean_types) # Filter for rows where the value in
# variable bean_type is present in the vector common_bean_types
⭐ Task 3-8
Make a boxplot of the rating chocolate bars received by most common bean types
Now remake your boxplot, but only for the most common bean types.
Check your code
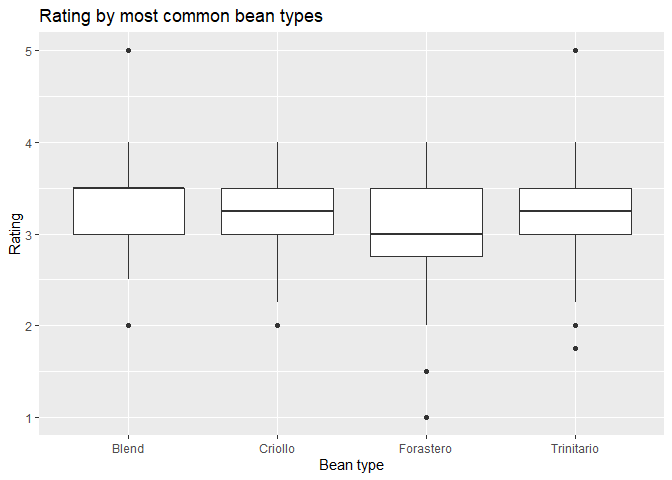
# Create plot by specifying data and assign variable to the y axis
ggplot(data = chocolateData_commonBeans, aes(y = rating, x = bean_type )) +
# then add a layer of boxplot
geom_boxplot() +
# add labels
labs(title = "Rating by most common bean types",
x = "Bean type",
y = "Rating")
Hint: use the newly created object chocolateData_commonBeans.
As you can see, the ratings of the most common bean types are not that different.
2.3. Scatter Plots
Not let’s apply the ggplot commands to create a scatter plot.
Definition - Scatter plot: A plot with two axes, each representing a different variable. Each individual observation is shown using a single point. The position of the point is determined by the value of the variables assigned to the x and y axes for that observation.
⭐ Task 3-9
Make a scatter plot of the cocoa percentage and the rating a chocolate bar received.
- Using chocolate data :
chocolateData - X-axis = Cocoa percentage:
cocoa_percent - Y-axis = Rating a chocolate bar received:
rating - Scatter plot function:
+ geom_point()
Check your code
# Create plot by specifying data and assign variables to x and y axes
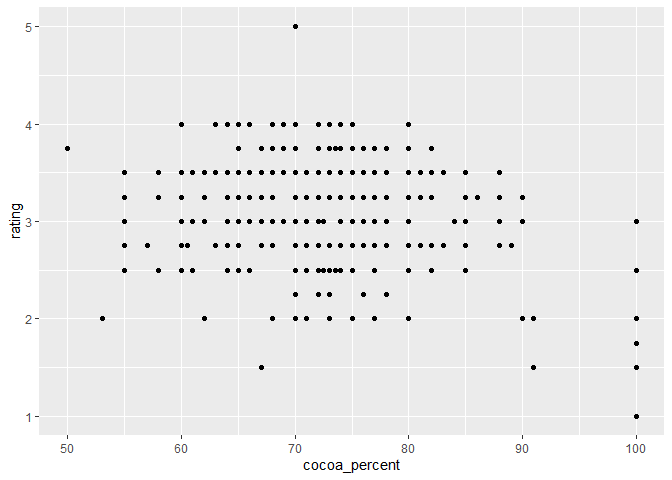
ggplot(data = chocolateData, aes(x = cocoa_percent, y = rating)) +
geom_point() # then add a layer of points
Before we add details to our plot, we need to learn about the different components. Wait until the next task to do anything.
Definition - Fitted line: (aka. a ‘line of best fit’) is a line representing some function of x and y that has the best fit (or the smallest overall error) for the observed data.
Function for adding a smooth line to a plot: geom_smooth(method = "") - method type specifies the type of smoothing to be used
Expand for more geom_smooth method types
- Linear Model (“lm”): fits a linear regression model, suitable for linear relationships.
- Locally Estimated Scatterplot Smoothing (“loess” or “lowess”): creates a smooth line through the plot by fitting simple models in a localized manner, which can handle non-linear relationships well. Ideal for smaller datasets
- Generalized Additive Models (“gam”): model complex, nonlinear trends in data. Ideal for larger datasets.
- Moving Average (“ma”): smooths data by creating an average of different subsets of the full dataset. It’s useful for highlighting trends in noisy data.
- Splines (“splines”): provide a way to smoothly interpolate between fixed points, creating a piecewise polynomial function. They are useful for fitting complex, flexible models to data.
- Robust Linear Model (“rlm”): Similar to linear models but less sensitive to outliers. It’s useful when your data contains outliers that might skew the results of a standard linear model.
- Fitted line:
method = "lm"
⭐ Task 3-10
Make another scatter plot of the cocoa percentage and the rating a chocolate bar received, with the following:
- A “line of best fit”
Remember:
- Using chocolate data:
chocolateData - X-axis = Cocoa percentage:
cocoa_percent - Y-axis = Rating a chocolate bar received:
rating - Line of best fit:
geom_smooth(method = "lm")
Check your code
# Create plot by specifying data and assign variables to x and y axes
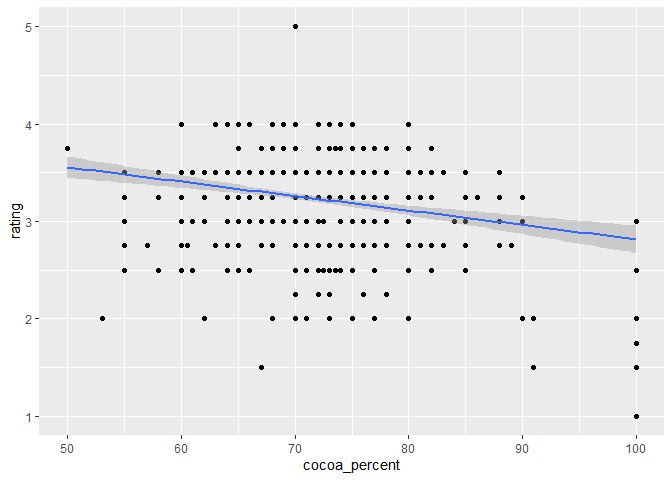
ggplot(data = chocolateData, aes(x = cocoa_percent, y = rating)) +
geom_point() + # then add a layer of points
geom_smooth(method = "lm") # add a fitted line using the lm method
⭐ Task 3-11
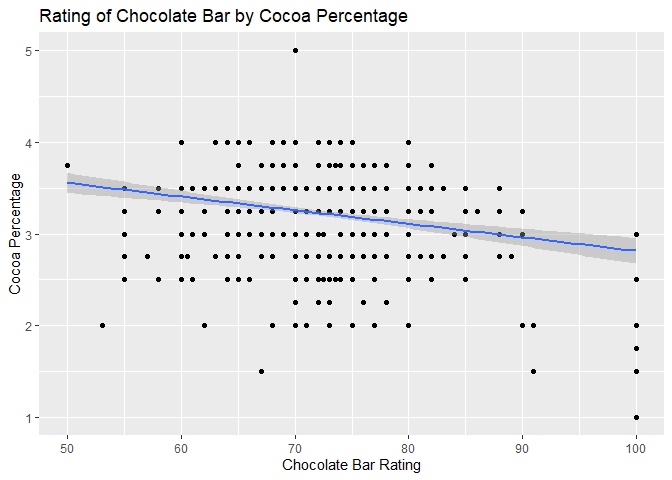
Add descriptive axis labels and a title to your scatter plot.
Now also add descriptive labels using the labs() function.
- Title: “Rating of Chocolate Bar by Cocoa Percentage”
- X-axis labels: “Chocolate Bar Rating”
- Y-axis label: “Cocoa Percentage”
Check your code
# Create plot by specifying data and assign variables to x and y axes
ggplot(data = chocolateData, aes(x = cocoa_percent, y = rating)) +
# then add a layer of points
geom_point() +
# add a fitted line using the lm method
geom_smooth(method = "lm") +
# Add labels to the plot
labs(title = "Rating of Chocolate Bar by Cocoa Percentage",
x = "Chocolate Bar Rating",
y = "Cocoa Percentage")
📍 Reminder! Save your work
2.4. Bar Charts
A bar chart shows the relationship between a categorical variable (on the x-axis) and a numerical variable (on the y-axis).
A common type of bar plot is one that illustrates categories along the x-axis and the count of observations from each category on the y-axis.
For this type of data, the call for bar charts in ggplot2 geom_bar() makes the height of the bar proportional to the number of observations in each group of a categorical variable, so you only need to tell ggplot2 the variable you want to use on the x-axis of your bar chart, and it makes the calculations for the y-axis in the background.
For example, let’s make a bar chart that shows the number of chocolate bars that are made for different types of cacao beans.
⭐ Task 3-12
Create a basic bar chart.
Your chart will illustrate the number of bars of different types of beans that are being made.
- Use the
chocolateDataobject inside the ggplot call - Specify the variable
bean_typefor the x-axis - Use
+ geom_bar()to plot a bar chart
Check your code
# Create plot by specifying the data and the variable for the x axis
ggplot(chocolateData, aes(x = bean_type)) +
# Add a layer of bars
geom_bar()
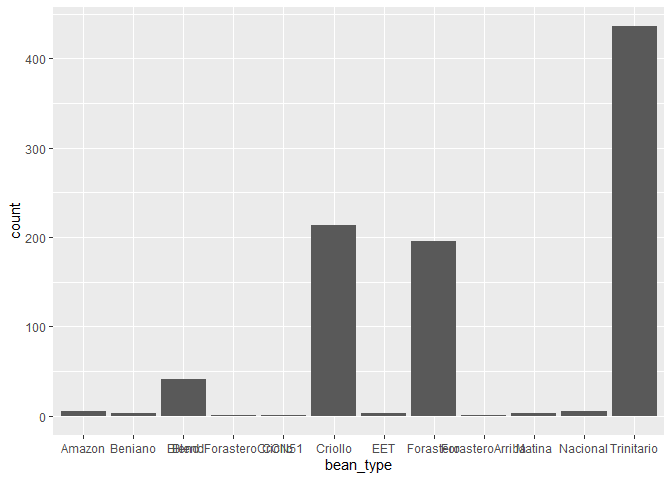
Hint: you do not need to specify anything for the y-axis in this case
Again, here the plot is hard to interpret, as there are many bean types that are not commonly made. In this case, it would be again best to plot only the most common bean types, in the same way we did for the boxplot.
⭐ Task 3-13
Create a basic bar chart.
Now remake your bar chart, but only for the most common bean types.
Check your code
# Create plot by specifying the data and the variable for the x axis
ggplot(chocolateData_commonBeans, aes(x = bean_type)) +
# Add a layer of bars
geom_bar()
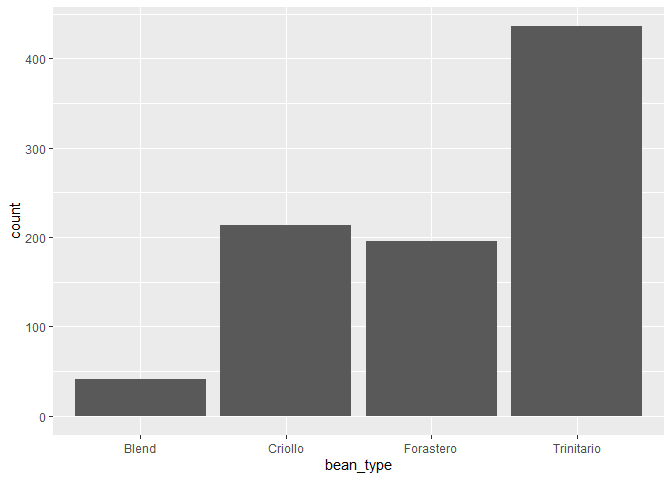
Another type of bar chart is the stacked bar chart. A stacked bar chart shows two dimensions (i.e., categorical variables) of data. Each bar will represent one category type, and each bar will be chopped into sections which represent a second category type.
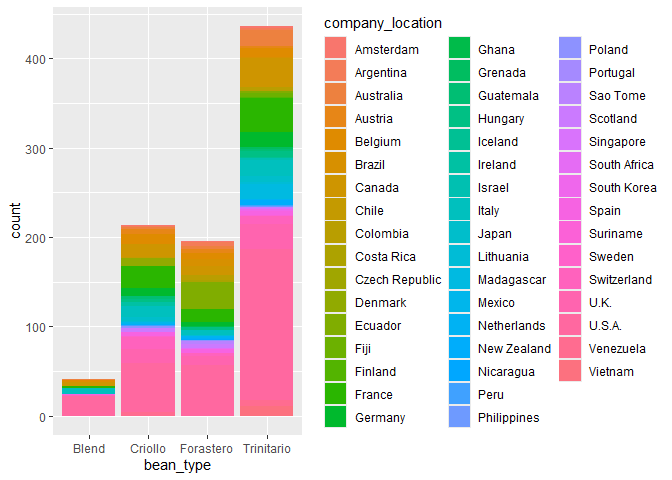
⭐ Task 3-14
Create a stacked bar chart.
To add a second dimension,
- following the same command as the bar chart above, modify it by:
- adding the parameter
fill = factor2nametoaes(), where ‘factor2name’ is the second variable’s column name. - setting the parameter of
geom_bar()toposition="stack"
- adding the parameter
For this task, use company_location as the second variable that will chop the bars of the most common bean types into sections.
Check your code
# Create plto by specifying data and variables assigned to x-acis and fill colour
ggplot(chocolateData_commonBeans, aes(x = bean_type, fill = company_location)) +
# Add a layer of bars, with stacked bars of different colours
geom_bar(position = "stack")
So far, we have looked at bar charts that plot the count of observations in different categories in the y-axis. But if we want the y-axis to show the values of actual variables in your data? For that situation, you can use the geom_col() function.
For example, imagine you want to plot the average rating for the different types of beans. First, you would need to calculate the average rating per bean type. To do this, you can use the group_by() and summarise() functions your learned in the previous section:
chocolateData_commonBeans_rating <- chocolateData_commonBeans |> # get the dataset
group_by(bean_type) |> # group by bean type
summarise( # summarise a variable for each bean type
mean_rating = mean(rating) # the summary is the mean rating
)
# see the results
chocolateData_commonBeans_rating
## # A tibble: 4 × 2
## bean_type mean_rating
## <chr> <dbl>
## 1 Blend 3.35
## 2 Criollo 3.27
## 3 Forastero 3.11
## 4 Trinitario 3.25
Then, you can use this new dataset to plot your bar chart.
⭐ Task 3-15
Create a bar chart using geom_col().
Use the object chocolateData_commonBeans_rating and the function geom_col() to plot a bar chart showing the average rating per bean type.
Check your code
# Create a plot by specfying the data and the variables assigned to x and y axs
ggplot(chocolateData_commonBeans_rating, aes(x = bean_type, y = mean_rating)) +
# add a layer of columns
geom_col()
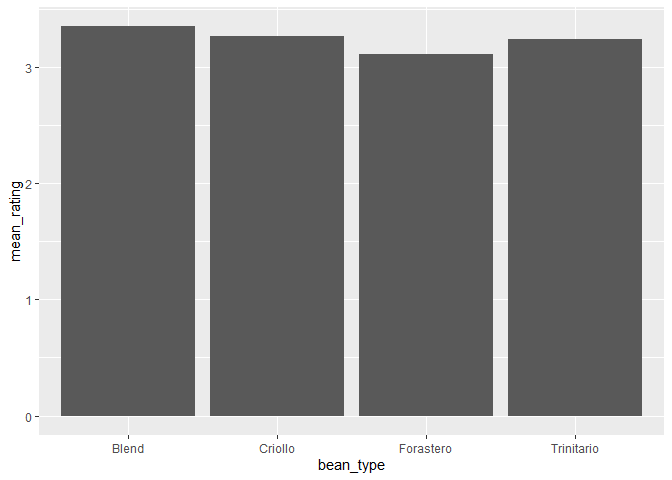
- Hint: you need to specify a variable for the y-axis when using
geom_col()
2.5. Line Charts
To create a line chart, let’s start first by creating a new variable that we might want to plot in a line chart. In this case, let’s assume we are interested in seeing how the average chocolate rating varies through the years.
⭐ Task 3-16
Create an object with the mean chocolate rating by year.
Using piping, create a new object, meanRatingByYear
- base data:
chocolateData - group_by:
review_date - use
summarise()and calculate the mean of the rating variables inside the summarise
Check your code
# Get the original dataset
meanRatingByYear <- chocolateData |>
# Group by review data
group_by(review_date) |>
# Get average rating for each review date
summarise(
rating = mean(rating)
)
# Now see the object created
meanRatingByYear
## # A tibble: 12 × 2
## review_date rating
## <int> <dbl>
## 1 2006 3.28
## 2 2007 3.30
## 3 2008 3.05
## 4 2009 3.13
## 5 2010 3.20
## 6 2011 3.27
## 7 2012 3.21
## 8 2013 3.28
## 9 2014 3.24
## 10 2015 3.28
## 11 2016 3.26
## 12 2017 3.5
- Hint: this will be very similar to when you calculated the mean rating by bean type above.
Now we are ready to make our line chart!
⭐ Task 3-17
Create a line chart using the mean chocolate rating by year.
Here we’ll make a line chart to show how the mean rating of chocolate has changed by year.
- Your base data will be the mean rating table you just created
- the x-axis value will be the review date
- the y-axis will be the rating
- the geom type is
geom_line(), with no parameter
After the geom type, you might want to add a line of code to make sure the x-axis label contains the actual years. For that, you can use the scale_x_continuous function, which take as the parameter breaks the vector of points to create axis breaks. To use the function, you have to use + scale_x_continuous(breaks = vectorofbreaks) at the end of your plot code.
Check your code
# Create the plot by specifying the data and the variables assigned to x and y axes
ggplot(meanRatingByYear, aes(x = review_date, y = rating)) +
# Add a layer of line
geom_line() +
# Corrects the breakpoints for the x axes
scale_x_continuous(
breaks = meanRatingByYear$review_date # Use actual review dates for breaks
)
⭐ Task 3-18
Style your line chart.
Using the same chart you just made, add some stylistic features and modifications.
- rename the x label to “Review Date”
- rename the y label to “Rating”
- Add a title: “Change in Rating Over Time”
Check your code
# Create the plot by specifying the data and the variables assigned to x and y axes
ggplot(meanRatingByYear, aes(x = review_date, y = rating)) +
# Add a layer of line
geom_line() +
# Corrects the breakpoints for the x axes
scale_x_continuous(
breaks = meanRatingByYear$review_date # Use actual review dates for breaks
) +
# Add labels
labs(
x = "Review Date",
y = "Rating",
title = "Change in Rating Over Time"
)
Congratulations! Now you know how to use ggplot2 to plot histograms, boxplots, scatter plots, bar charts and line charts!
📍 Reminder! Save your work
⭐ Optional challenge
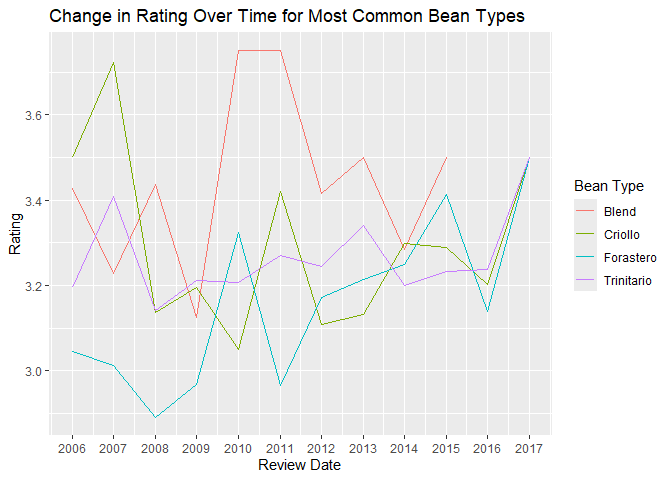
Plot the change in rating over time for the 4 most common bean types
Create a line chart similar to the one above, but instead of just the one line across all chocolates, plot four lines, one for each most common bean type.
Steps:
- Create a dataframe with the mean rating by year for each most common bean type.
- Start with the dataset
chocolateData_commonBeans - Use
group_by()andsummarize()just as above, but group by bothreview_dateandbean_type
- Start with the dataset
- Use the dataframe created to plot the line chart.
- Inside the
aes()function, map the aestheticscolour(i.e. the colour of the line) to thebean_typevariable
- Inside the
Check your code
# Get the dataset of most common bean types
meanRatingByYearType <- chocolateData_commonBeans |>
# Group by review date and bean ty[e]
group_by(review_date, bean_type) |>
# Get average rating for each review date and bean type
summarise(
rating = mean(rating)
)
# Now see the object created
meanRatingByYearType |>
head(5)
## # A tibble: 5 × 3
## # Groups: review_date [2]
## review_date bean_type rating
## <int> <chr> <dbl>
## 1 2006 Blend 3.43
## 2 2006 Criollo 3.5
## 3 2006 Forastero 3.05
## 4 2006 Trinitario 3.20
## 5 2007 Blend 3.23
# Create the plot by specifying the data and the variables assigned to x and y axes, as well as colour
ggplot(meanRatingByYearType, aes(x = review_date, y = rating, colour = bean_type)) +
# Add a layer of lines
geom_line() +
# Corrects the breakpoints for the x axes
scale_x_continuous(
breaks = meanRatingByYear$review_date # Use actual review dates for breaks
) +
# Add labels
labs(
x = "Review Date",
y = "Rating",
colour = "Bean Type",
title = "Change in Rating Over Time for Most Common Bean Types"
)